理解报表数据模型:概述和查询设计
概述
报表数据模型是一个允许定制报表的维度模型。维度建模是一种数据仓库技术,它公开了围绕业务流程的信息模型,同时提供了生成报告的灵活性。报告数据模型的实现使用的是PostgreSQL关系数据库管理系统,版本为9.0.13。因此,在针对报表数据模型设计报表时,可以利用PostgreSQL的语法、函数和其他特性。
报表数据模型作为嵌入式关系模式可用,可以使用自定义报表模板对其进行查询。当将报表配置为使用自定义报表模板时,该模板将针对报表数据模型的一个实例执行,该实例使用与报表配置一起定义的设置确定范围并进行筛选。以下设置将指定在执行自定义报表模板期间可用的信息。
报告老板
报表的所有者指定报表数据模型公开哪些数据。报表所有者的访问控制和角色指定了在报表中可以选择和访问的范围。
范围的过滤器
范围过滤器定义哪些资产、资产组、站点或扫描将在报告数据模型中公开。这些实体,以及匹配的配置选项,如“仅使用最近的扫描数据”,指示在生成时哪些资产将对报告可用。范围筛选器还在维度中公开,以便允许设计人员输出嵌入在报告中的信息,这些信息可以在需要的情况下确定生成期间的范围。
脆弱性过滤器
漏洞过滤器定义哪些漏洞(和结果)将在数据模型中暴露。在生成报告之前有三种类型的过滤器:
- 严重性:根据最低严重性级别将漏洞过滤到报告中。
- 类别:根据与漏洞相关的元数据将漏洞过滤到报告中或过滤出报告。
- 状态:根据结果状态将漏洞过滤到报告中。
查询设计
通过使用嵌入到定制报表模板设计中的查询,可以访问报表数据模型中的信息。
维度建模
维度建模通过事实和维度的组合来呈现信息。事实是存储测量数据的表,通常是数值的,并具有可添加的属性。事实表以前缀“fact_”命名,表示它们存储的是事实数据。每个事实表记录都是在相同的粒度级别上定义的,这是事实的粒度级别。谷物指定了测量记录的水平。
维度是伴随测量数据的上下文,通常是文本的。维度表以前缀“dim_”命名,表示它们存储上下文数据。维度允许以对业务有意义的方式对事实进行切片和聚合。事实表中的每条记录都没有指定主键,而是定义了一组一对多的外键,这些外键链接到一个或多个维度。每个维度都有一个主键,用于标识可能被连接的相关数据。在某些情况下,维度的主键是多个列的组合。事实表和维度表中的每个主键和外键都是代理标识符。
标准化和关系
与传统的关系模型不同,维度模型支持反规格化,以减轻查询设计人员的负担并提高性能。每个事实及其相关维度组成了通常所说的“星型模式”。从视觉上看,事实表被多个维度表所包围,这些维度表可用于对事实进行切片或连接。在使用星型模式样式的完全非规范化维度模型中,事实和维度之间只有关系,但维度是完全自包含的。当维度没有完全去规范化时,它们可能与其他维度存在关系,当一个维度中存在一对多关系时,这种关系很常见。当这种结构存在时,事实和维度就构成了“雪花模式”。这两个模型都有一个共同的模式,即单一的中心事实表。当设计一个查询来解决业务问题时,只有一个模式(因此只有一个事实)应该被使用。
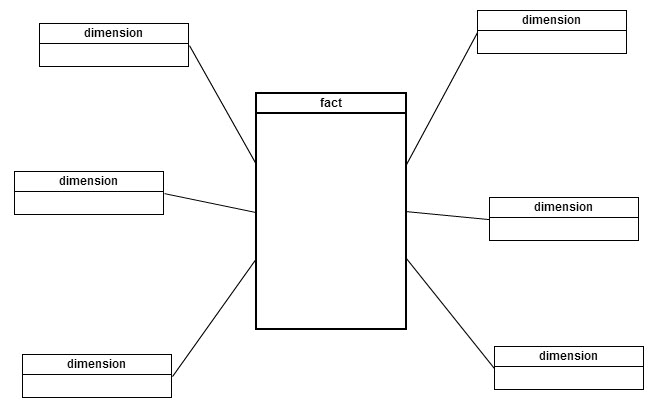
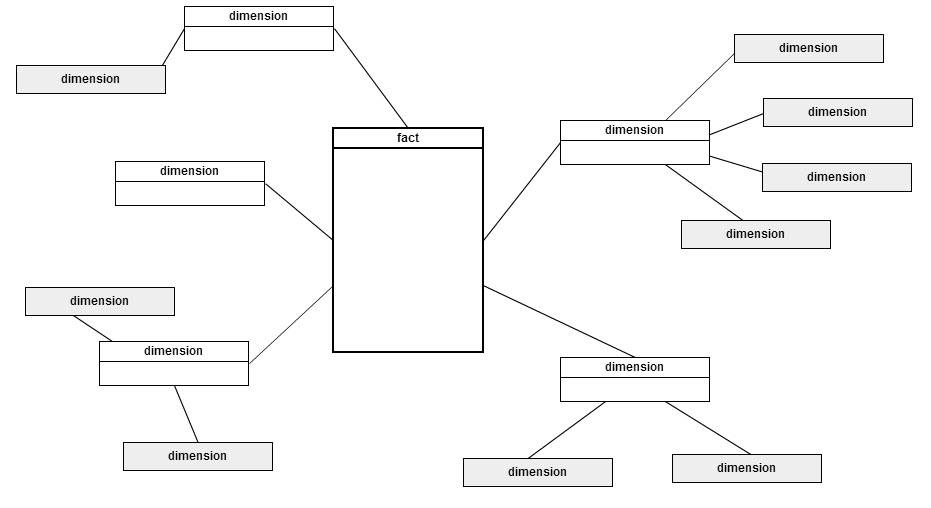
事实表类型
存在三种不同类型的事实表:(1)事务表(2)累积快照和(3)周期快照。事务事实的粒度级别是在某个时间点发生的事件。事务事实识别伴随离散的动作、过程或活动的度量,这些动作、过程或活动是以不规则的间隔或计划执行的。累积快照事实将随时间或多个事件度量的信息聚合到单个合并度量中。该测量显示了谷物在某一水平上的当前状态。定期快照事实表提供按定期间隔(通常按天或日期)记录的度量。每条记录都测量了一个离散时刻的状态。
维度表类型
类型维度表通常根据它们提供的维度数据的性质进行分类,或者指示它们更新的频率(如果有的话)。
以下是维度模型中经常遇到的维度类型,以及报表数据模型所使用的维度类型:
- 缓慢变化维度(SCD).缓慢变化维度是指其信息以不规则的间隔随时间缓慢变化的维度。缓慢变化的维度进一步按类型分类,类型表示表中记录变化的性质。报告数据模型中最常用的类型是类型I和类型II。
- 类型I SCD会随着时间的推移覆盖维度信息的值,因此它会积累信息的当前状态而不是历史状态。
- 类型II SCD随着时间的推移将值插入到维度中,并累积历史状态。
- 符合尺寸.一致性维度是由具有相同标签和价值的多个事实共享的维度。
- 垃圾的维度.垃圾维度是那些不适合传统核心实体维度的维度。垃圾维度通常由标志或其他相关值组组成。
- 正常的尺寸.正常维度是没有标注在任何其他专门化类别中的维度。
空值&未知
在维度模型中,事实表中的外键使用NULL值是一种反模式。因此,当维度的外键不应用时,将在事实记录中放置该键的默认值(值为-1)。此值将允许对维度的“自然”连接检索“Not Applicable”或“Unknown”值。“Not Applicable”或“N/A”的值意味着该值不是为事实记录或维度定义的,并且永远不会有一个有效值。“Unknown”的值表示无法确定或评估该值,但可以有一个有效值。这种做法鼓励在事实与其相关维度之间进行连接时使用自然连接(而不是外部连接)。
查询语言
由于报表数据模型公开的维度模型构建在关系数据库管理系统上,访问事实和维度的查询是使用结构化查询语言(SQL)编写的。可以利用PostgreSQL DBMS支持的所有SQL语法。星型或雪花型模式设计的使用鼓励在大多数查询中使用可重复的SQL模式。这种模式如下所示:
维度模型查询的典型设计
SELECT column, column,…
从fact_table
JOIN dimension_table ON dimension_table。primary_key = fact_table.foreign_key
加入……
dimension_table的地方。Column = some condition…
...以及其他SQL构造,如GROUP BY、HAVING和LIMIT。
SELECT子句投射需要返回的所有数据列,以填充或填充报表设计的各个方面。这个子句可以使用聚合表达式、函数和类似的SQL语法。FROM子句的构建方法是,首先从单个事实表中提取数据,然后对周围的维度执行join。通常只需要自然连接就可以对维度进行连接,但外部连接可能需要根据具体情况进行连接。针对维度模型的查询中的WHERE子句将根据事实或维度中的数据的条件进行筛选,这取决于筛选器是数值的还是文本的。
从查询返回的列的数据类型将是任何PostgreSQL DBMS支持的数据类型。如果在查询中投影的列是维度的外键,并且没有适当的值,那么将根据数据类型使用哨兵。这些值表示不适用或未知,具体取决于维度。如果数据类型不能支持转换为文本“Unknown”或类似的哨兵值,则使用NULL。
数据类型 |
未知的价值 |
|---|---|
文本 |
“未知” |
macaddr |
零 |
inet |
零 |
性格,性格不同 |
“- - -” |
长整型数字、整数 |
-1 |
查询的第一行不能是SQL注释。查询中使用的任何SQL注释都不能包含分号。
数据模型2.0.0公开了关于跨站点链接资产的信息。所有以前的信息仍然可用,并且格式相同。在数据模型2.0.0中,有一个网站列在dim_asset维度中,该维度列出资产所属的站点。